

How to Become a Machine Learning Engineer Without a Degree
Becoming a machine learning engineer without a degree is achievable through alternative educational paths and hands-on experience. Start by gaining a solid understanding of mathematics, particularly linear algebra, calculus, and statistics, as these are fundamental to machine learning algorithms.
Leverage free and paid online resources, such as Coursera, edX, and Udacity, to take courses in machine learning, data science, and programming languages like Python and R. Engage in practical projects to apply your knowledge; platforms like Kaggle offer datasets and competitions that can help you build a portfolio. Additionally, contribute to open-source projects and collaborate with others in the field to hone your skills.
Networking through tech meetups, conferences, and online communities can open opportunities for mentorship and job placements. Finally, consider obtaining professional certifications from recognized institutions to validate your expertise and make you stand out to potential employers.
Understanding Machine Learning
What is Machine Learning?
Machine Learning (ML) is a type of Artificial Intelligence (AI) that allows computers to learn and make decisions from data. Think of it as teaching a computer to recognize patterns and make predictions without being explicitly programmed for every task.
Why Python?
Python is one of the most popular programming languages for machine learning. It’s easy to learn and has many libraries that make it perfect for beginners. Start with Python for Machine Learning courses available on platforms like Coursera and Udemy.
Key Concepts in Machine Learning
Core Algorithms
Understanding the main machine learning algorithms is crucial. These include:
- Linear Regression: This predicts a value based on past data.
- Decision Trees: These help computers make decisions by splitting data into branches.
- Support Vector Machines (SVM): These classify data into different categories.
Neural Networks
Neural Networks are a key part of machine learning. They are models that mimic how the human brain works, helping computers recognize patterns and learn from data. Start with the basics of neural networks through simple tutorials.
Getting Hands-On Experience
Projects and Practice
One of the best ways to learn is by doing. Start small with projects like predicting house prices using linear regression. As you grow more confident, tackle more complex projects like image recognition or language translation.
Competitions
Joining Kaggle competitions is a great way to test your skills. These competitions present real-world problems that you need to solve using machine learning. They also provide a community where you can learn from others.
Advanced Learning Resources

Deep Learning and Tensor Flow
Once you’re comfortable with the basics, dive into deep learning. Use Tensor Flow, a powerful tool created by Google, to build advanced models. Work on Tensor Flow projects to see your learning in action.
Data Science Tools
Familiarize yourself with tools like Jupyter Notebooks for writing and running code and PyCharm for a more advanced coding environment. These tools will help you work more efficiently.
Expanding Your Knowledge
Specialized Libraries
Explore specialized machine learning libraries such as Keras for building neural networks and XGBoost for gradient boosting. These libraries offer advanced features that can help you solve more complex problems.
Data Analysis Techniques
Learn data analysis techniques to clean and prepare your data. This includes handling missing values, normalizing data, and engineering features to improve your model’s performance.
Joining the Community
Forums and Meetups
Join machine learning community forums like Reddit’s r/Machine Learning and Data Science Stack Exchange. Attend local meetups and conferences to network with other professionals and stay updated on the latest trends.
Reading Research Papers
Stay current by reading machine learning research papers. Websites like arXiv.org and Google Scholar provide access to the latest research in the field.
Preparing for the Job Market
Online Coding Bootcamps
Enroll in online coding bootcamps for structured learning and career support. These bootcamps offer intensive training and often include career services to help you find a job.
Self-Study and Interview Prep
If you prefer self-paced learning, use online resources and textbooks to study machine learning. Prepare for job interviews by practicing common machine learning interview questions on platforms like Leet Code and Hacker Rank.
Showcasing Your Work
Building a Portfolio
Create a portfolio showcasing your projects. Include your work on GitHub and any contributions to open-source projects. This will help you stand out to potential employers.
Real-World Applications
Work on real-world machine learning applications like stock price prediction or natural language processing. These projects can demonstrate your skills and attract the attention of employers.
Ethics and Apprenticeships
AI Ethics
Understand the importance of AI ethics and ensure your models are fair and unbiased. This is crucial for maintaining the integrity of your work and building trust with users.
Apprenticeships
Look for machine learning apprenticeships to gain hands-on experience and mentorship. These programs provide practical learning and valuable industry insights.

Learn about Neural Networks?
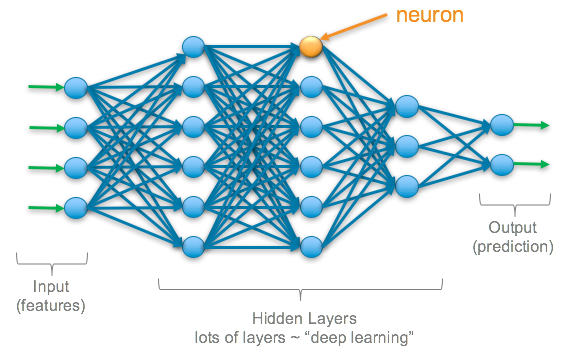
A neural network is a computational model inspired by the way biological neural networks in the human brain work. They are designed to recognize patterns, make decisions, and learn from data. Neural networks are a key component of many machine learning and artificial intelligence (AI) applications.
Basic Structure of a Neural Network
A neural network consists of layers of nodes (also known as neurons). These layers include:
- Input Layer: This layer receives the initial data.
- Hidden Layers: These layers process the input data through a series of transformations. There can be multiple hidden layers in a neural network.
- Output Layer: This layer produces the final output, such as a classification or a prediction.
Example of a Simple Neural Network
Below is a simple visual representation of a neural network:
Input Layer -> Hidden Layer(s) -> Output Layer
[x1, x2] [h1, h2, h3] [y]
How Neural Networks Work
Step-by-Step Process
- Input Data: The process begins with the input layer, where data is fed into the network. Each input feature is represented as a node.
- Weights and Biases: Each connection between nodes has an associated weight, which determines the strength of the connection. Each node also has a bias, which allows the activation of the node to be shifted up or down.
- Activation Function: The weighted sum of the inputs is passed through an activation function. This function introduces non-linearity into the model, enabling it to learn more complex patterns. Common activation functions include the sigmoid function, ReLU (Rectified Linear Unit), and tanh (hyperbolic tangent function).
- Forward Propagation: The input data moves forward through the network, layer by layer, until it reaches the output layer. During this process, the data is transformed by the weights, biases, and activation functions of each layer.
- Output: The final layer produces the network’s output, such as a predicted class label or a numerical value.
Training a Neural Network
Training a neural network involves adjusting the weights and biases to minimize the difference between the predicted output and the actual target values. This process is typically done using an algorithm called backpropagation, combined with an optimization technique like gradient descent.
Steps in Training:
- Initialization: Randomly initialize the weights and biases.
- Forward Propagation: Compute the output of the neural network for a given set of inputs.
- Loss Calculation: Calculate the loss (error) between the predicted output and the actual target values using a loss function. Common loss functions include Mean Squared Error (MSE) for regression tasks and Cross-Entropy Loss for classification tasks.
- Backward Propagation: Calculate the gradient of the loss with respect to each weight and bias using the chain rule of calculus.
- Weight Update: Adjust the weights and biases to minimize the loss using an optimization algorithm like gradient descent.
- Iteration: Repeat the process for many iterations (epochs) until the network’s performance improves.
Example of an Activation Function: ReLU
The Rectified Linear Unit (ReLU) function is one of the most popular activation functions. It is defined as:
ReLU(x)=max(0,x)ReLU(x)=max(0,x)
This means that any negative input is set to zero, while positive inputs remain unchanged.
Visualization of ReLU
Input: [-2, -1, 0, 1, 2]
Output: [ 0, 0, 0, 1, 2]
Applications of Neural Networks
Neural networks are used in various applications, including:
- Image Recognition: Identifying objects or faces in images.
- Natural Language Processing (NLP): Tasks like sentiment analysis, language translation, and text generation.
- Speech Recognition: Converting spoken language into text.
- Game Playing: AI agents that can play games like chess and Go.
- Medical Diagnosis: Assisting doctors in diagnosing diseases based on medical images or patient data.
Conclusion
Neural networks are powerful tools that can learn complex patterns and make accurate predictions. By understanding their structure and functioning, you can begin to harness their potential in various fields. Whether you’re working on image recognition, NLP, or any other data-driven task, neural networks offer a versatile and effective approach to problem-solving.
How to Become a Machine Learning Engineer Without a Degree
How to Find High-Paying Remote Jobs in 2025
Best countries for job opportunities 2025
Location Independent Careers
Top Remote Jobs for Digital Nomads in 2025
ASSET AND CONFIGURATION MANAGEMENT PROCESS AND TECHNOLOGY MANAGER





")



{kind=link}